好久没更新,主要文件系统实际实现这段看完一次没有很看懂,过了段时间又看了第二次加深了理解,才好做总结
本章主要讲解了一下文件系统最简单的实现,以及设计一个文件系统需要考虑哪些点。
文件系统基本的数据结构
一个文件系统基本的数据接口,首先一般会将磁盘划分为多个固定大小的Region,这个Region你可以认为是页,理所当然,页的大小就是4k(内存页)。
然后,我们看下文件系统包含哪些数据结构类以及他们的作用
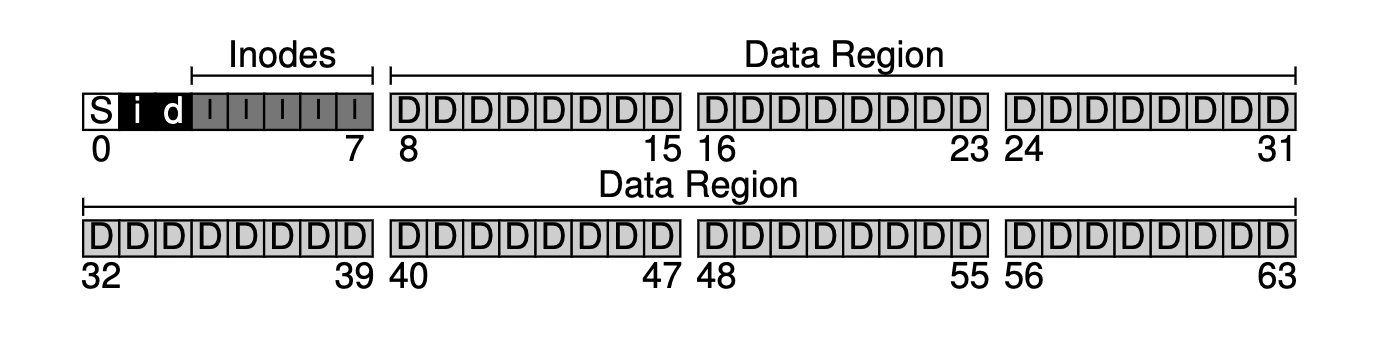
和文中顺序一样吧,我们倒着来,方便理解。
- D:D表示数据区域,就是实际保存数据的数据节点,里面存的就是实际需要保存的用户数据
- I(Inodes):Inodes就是文件的源信息(metadata)保存的节点,里面保存的数据是一个个Inode,每个Inode里面保存了文件的源信息,包括文件的名称、创建时间、所有者、权限、以及实际对应的文件的Data Region信息。
- Inodes前面的i、d:这实际上是2个bitmap,就是inode和Data Region的2个bitmap,用来记录Inode和Data Region的使用情况,bitmap中第n位表示第n个Inode或者Data Region是未使用的
- S: 记录了整个文件系统的源数据,比如Inodes的数量,Data Region的数量,还有他们这两个区域起始的位置,还会用一个魔法数的枚举来表明文件系统的类型(fat32,NTFS)。
Inodes对于Data Region的记录
Inodes中需要记录的就是文件的源信息,以及这个文件对应的Data Region,那么如何支持大文件就会成为一个问题,当一个Inode表示一个文件时,他至少需要一个数组来表明这个文件使用了哪些Data Region,比如使用了(8,9,10,11),但是当这个场景扩展到大文件时,这个数组就会过大。
解决思路其实很简单,和内存的解决思路相似,使用间接指针。Inode中改为只指向一个Data Region,但是那个Data Region中保存的多层树结构(是不是很像多级页表?),这些树上的结点就是那些Data Region的信息。实际上就是把线性的表达转移到用户存储的Data Reigon中,并且使用树这种更高效的数据结构来存储。
另一种思路也是类似于内存的表达,就是段表达,即通过记录文件保存在哪些连续的Data Region段中,比如(8,20),(30,31)。段表达在大部分数据是连续时具有更好的性能。并且,因为连续的文件对于读写性能的提升很大,所以操作系统在分配文件空间时,往往也会选择将一个文件分配在连续的Data Region中,段表达在这种背景下,会是一个非常好的选择。
目录的保存
这里其实很简单,目录作为一个树状结构,也是保存在用户数据Data Region中的一颗树,其中每个节点保存的就是对应的那个文件的Inode。
杂项
后面的内容和东西很杂,毕竟这一章整章也只是为了开阔思路带你思考文件系统实现的要点,所以这边比较零散的总结一些点。
访问一个文件的IO次数要比想象的多得多
很容易根据Inode和Data Region的设计想到,读取或者写入一个文件需要非常多次的IO
比如读文件,就至少需要遍历一次目录找到文件的Inode,然后从Inode中读取到文件存储的Data Region的位置信息,然后再去读取到该文件。
写入则更复杂,除了读取的那些操作都需要操作一次外,还需要写入inode和Data Region的bitmap,此外,如果是创建文件的话,在目录树中也需要写入新文件的信息。
缓存
因为访问一个文件的IO远比想象的多,所以理所当然的会想到给一些必要的数据结构和信息加内存中的缓存,比如Inode,目录树,Inode记录的Data Region等。
缓存也有2种,一种是在内存中使用固定数量的内存页专门做缓存,然后在这部分空间中使用一些页面汰换算法。
大部分操作系统使用的是另一种,将这些数据结构也视为普通数据,作为正常的内存页加载到内存中,和普通的内存页一起参与汰换,这样的优点就是更加灵活,也避免了固定内存做缓存的多余空间浪费。
缓冲
前面提过,在发生写时,操作系统并不一定立马执行,而是可能将一堆写请求先放在buffer缓冲中,然后固定时间(一般是5-30秒)或者当buffer满了时,统一处理这些写请求。这样的好处是可以对IO次数以及写性能进行显著的优化。比如:
- 可以将连续的写请求合并成一个提交给硬盘,而不是多次,这样硬盘也会更好调度。
- 如果一个文件先创建后马上删除,那么这个写实际是可以取消的,避免了无效写
当然,如果你想要强保存,那么可以使用fsync()来直接写入物理硬盘,许多软件支持的强力保存以及当你使用Ctrl+S时,就是基于该API来实现的。
