这一章还真的有点复杂和晦涩
上一章讲了base和bound的概念,base和bound通过2个寄存器直接描述进程的物理内存起止,并且可以通过base+虚拟内存中的偏移量得到实际访问的物理内存地址。
段的基本概念和基本设计
本章提出了一个新问题:按照第13章中描述的进程内存模型
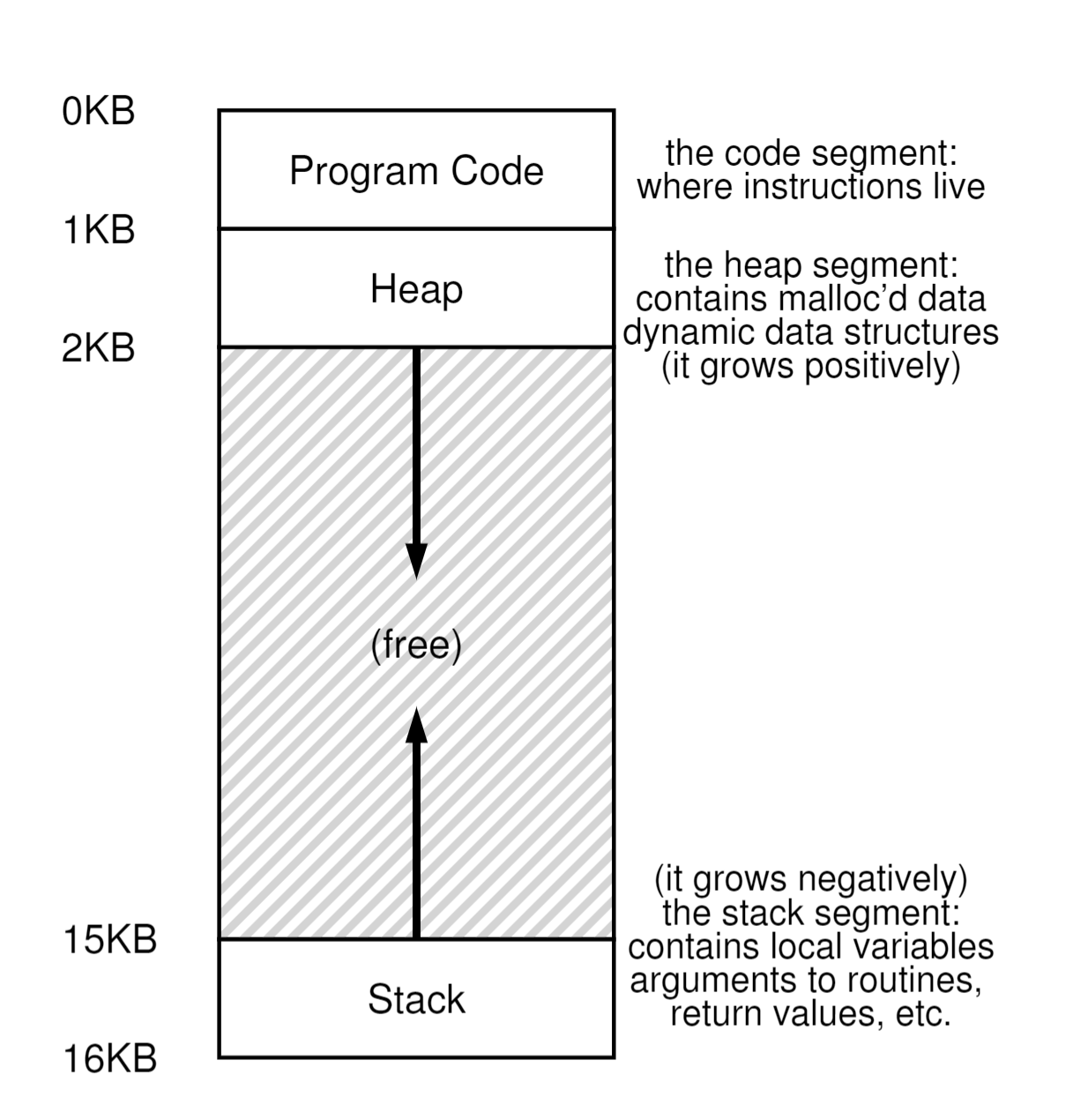
按照进程内存模型,一个进程的虚拟内存如果是连续的话,其中堆和栈之间的虚拟内存地址在应用实际申请前是完全浪费的,并且大小也不可预估,所以就提出了段的概念,来作为逻辑上的进程内存分割。实际上就是我们把进程的内存模型如果认为分为3部分,即code、heap、stack的话,我们完全可以使用3对base+bound将他们视作三段不同的逻辑分段。注意我们这里讨论的段只生效在虚拟内存模型里,虚拟内存到物理模型的转换还是使用base+bound的模型去转化
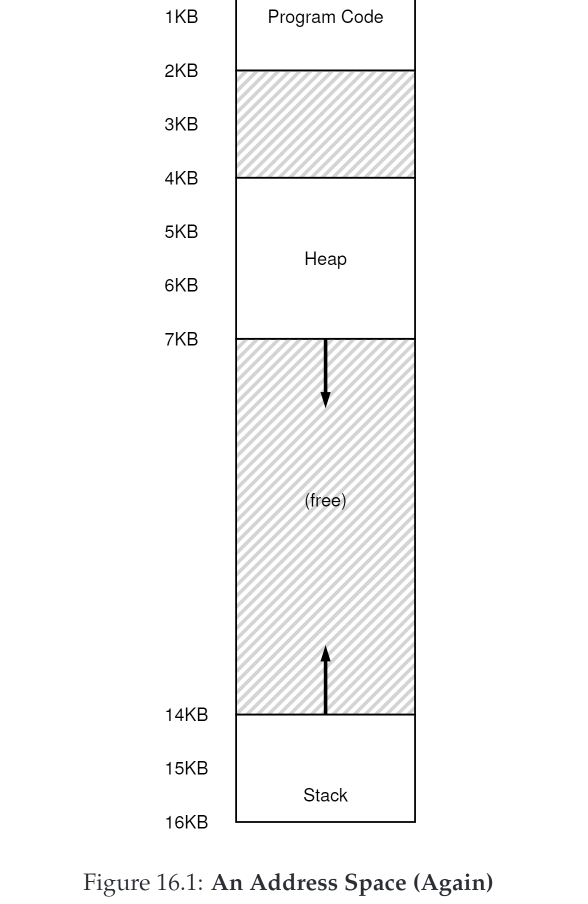
如图文中16.1中表示的这样,实际也就是可以认为这三段在虚拟内存的逻辑上也完全可以是不连续的,这样可以提高虚拟内存地址空间的使用效率。结合一个base+bound表16.3以及16.1,我们来看下这种方式如何运作
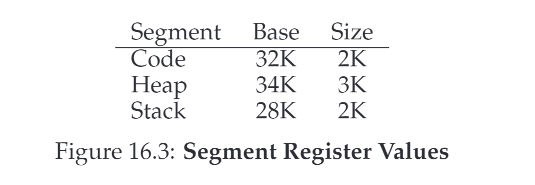
假设我们要访问一个虚拟内存中偏移为100的内存,那么因为他在Code段中,所以我们可以得到他的物理地址为$ 32768+100=32868$,并且可以通过100来检查内存是否越界访问了。
如果是堆,那么会稍微复杂一点。假设我们要访问偏移为4200的内存,因为这个偏移4200的内存实际位于的段是Heap段,所以我们需要再计算一下实际这个数值针对该Heap段的偏移,我们可以从16.1中看到Heap段在虚拟内存中起始位置是4K,所以实际4200针对Heap端的偏移为$ 4200-4096=104$,那么它的物理地址就是$34816+104=34920$
段的类型?
我们可以看到目前的计算都基于16.1,我们从图中知道了对应的虚拟地址上所属于的是怎样的段。但是实际对于OS来说,却没有这么简单,因为这些段都是动态分配并且没有图给OS看。所以针对段的类型,一般有两种方式来标记。
显式标记
一种方式就是显式标记,显式标记非常简单,对于任何一个虚拟地址的值,我们使用前两位来表示段的类型,后续位置表示在该段上的偏移量,如图
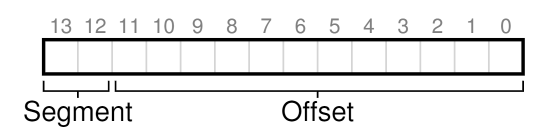
比如说,上面的4200位置,在这种表示方式下,虚拟地址就应该是
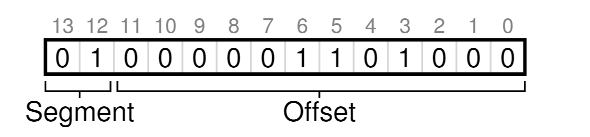
其中起始的2位01表示是Heap段,后续的12位即000 0110 1000, 就是我们计算的结果104
显示标记有几个缺点:
- 前两位可以表示4个状态,但是实际我们只有3个类型的段,有一丢丢浪费。所以通过对于code以及heap段基本是相同的处理逻辑(都是向下增长)考虑,将code和heap认为是一个类型,这样1位就可以表示了
- 使用了2位后,实际地址空间缩小了一个很大的量级去使用,比如这里例子上,14位系统只能用13位表示实际偏移量,虚拟地址空间实际可表示大小缩小了2倍,如果使用2位,那么缩小了4倍
隐式标记
还有一种隐式标记的处理方式,逻辑也非常简单:通过这个地址段是如何形成的来决定类型。比如通过程序计数器PC生成的,那么肯定是code段。如果地址是基于栈或者基准指针,那么肯定是stack段。其余的都认为是heap段
如何处理栈的偏移计算?
这里涉及到另一个寄存器需要增加的状态位:正负。这里的正负是指的偏移计算的正负,因为我们知道堆是向下增长的,而栈是向上,在计算偏移的时候,CPU需要了解到这个正负来快速计算。(你不能指望CPU根据段的类型写个if else,这将完全破坏CPU的单一功能并且将CPU和OS的段设计完全耦合,要知道虚拟地址空间的设计是OS的设计不是CPU的设计)

这个表中多了一个max4K,这个需要注意一下,这个表示了端的最大偏移大小,这个值不需要额外的寄存器保存,因为在我们的显示标记表达法下,这个值是显而易见的固定值——在14位的机器中,前2位被使用表达了端类型,剩下的12位表示偏移量,12位能表达的最大偏移量就是4k
这样让我们来计算一下这种情况下stack的实际物理地址。当我们想要访问虚拟内存的15k时,实际对应的是物理地址的27k。在我们的显示标记表达法之下,转换的地址值就是: 11 1100 0000 0000 (hex 0x3C00),其中前2位11表示了这个段的类型是栈,然后剩下的偏移量3k,我们通过3k-4k(因为是负向增长,所以需要减去偏移范围最大值才是实际的偏移)得到-1k,此时对应的物理地址28k直接+上面得到的-1k就得到了实际的物理地址27k。
此时计算范围也很简单,依旧是对比得到的负偏移值-1k的绝对值小于实际size2k即可。
通过段来支持共享内存
聪明的前辈开发者们很快了解到,再加一个标记位来表示这块内存的保护状态
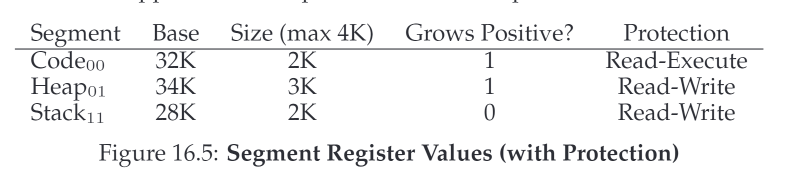
这样就可以通过保护位的标记,来使得同一个段在不同进程之间有不同的访问状态,多个进程可以对同一个内存段执行或者读取。比如你直接跨进程调用他们的方法。或者通过访问公共信号量来进行通信
段的颗粒度以及内存碎片压缩
段的颗粒度可以有粗有细,像最粗的粒度(code,heap,stack),可能会导致内存的利用率低。细粒度也有缺点,需要额外的段表来进行管理,但是带来的好处是OS可以通过段表对内存做更加高效的管理。
因为段的形式,所以内存中会出现大量的内存碎片,原文中称之为外部碎片external fragmentation。下图就很形象的表示了
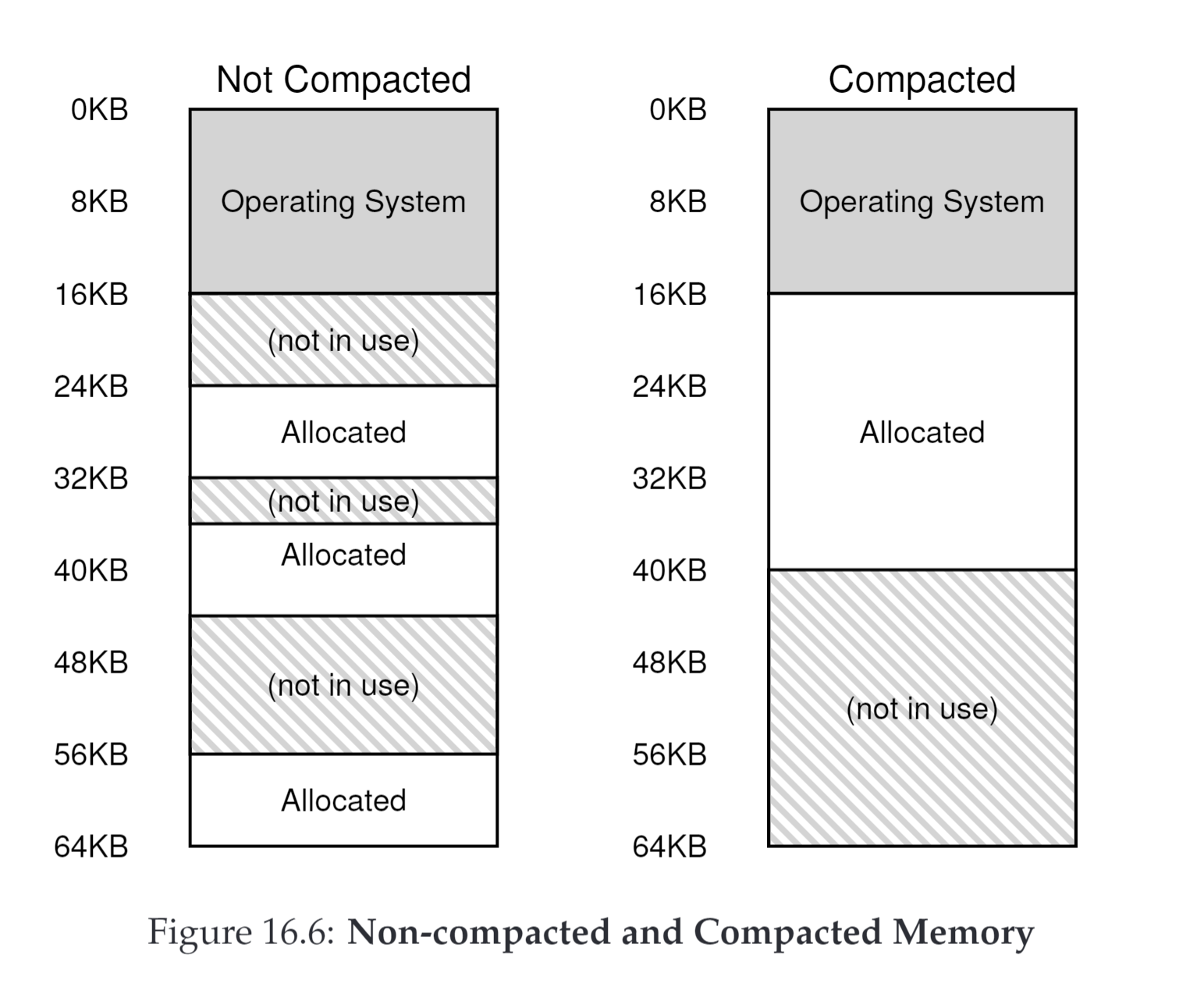
碎片主要影响OS在进程申请新的段或者扩大原有段时的操作,多个碎片合并可能可以满足新的内存申请需求,但是单个碎片却不行。
一个解决问题的办法就是经常去压缩内存,也就是把分配的重新迁移复制到一起,类似于java的gc,将所有allocated移动到内存头部,剩余的自然就变成了一大块内存。但是这样会带来很大的CPU消耗
下一章介绍的是空闲内存的管理,会进一步解决这个内存压缩的问题
由此章可见,虚拟化内存是多么复杂,如此多的步骤也只介绍了虚拟化内存工作的冰山一角。虚拟化内存要解决的问题远比虚拟化cpu要多得多。