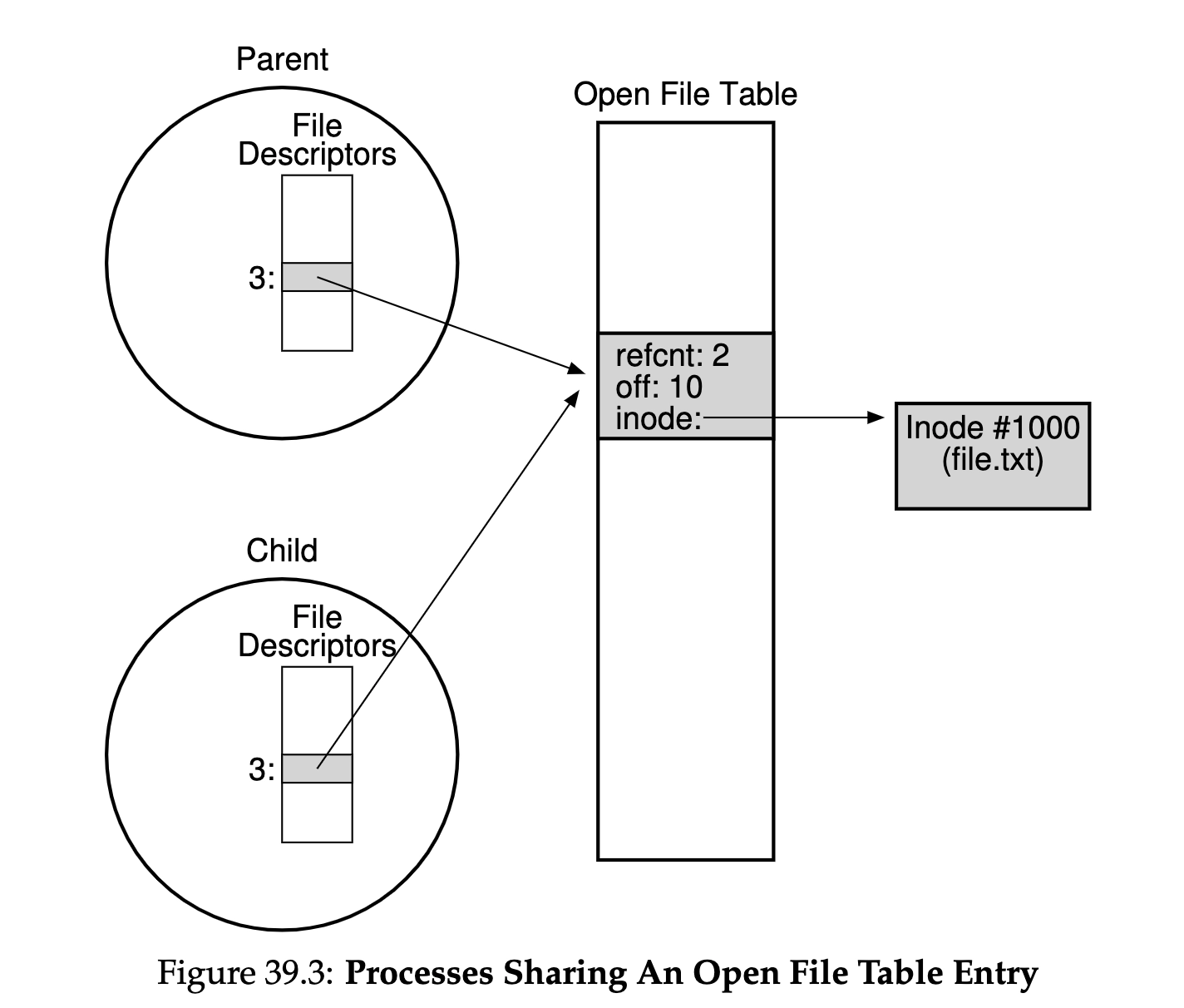
这章主要聚焦到了编写硬盘驱动上。
在开始编写之前,我们首先需要知道硬盘的实际构造以及查询逻辑。
磁盘构造
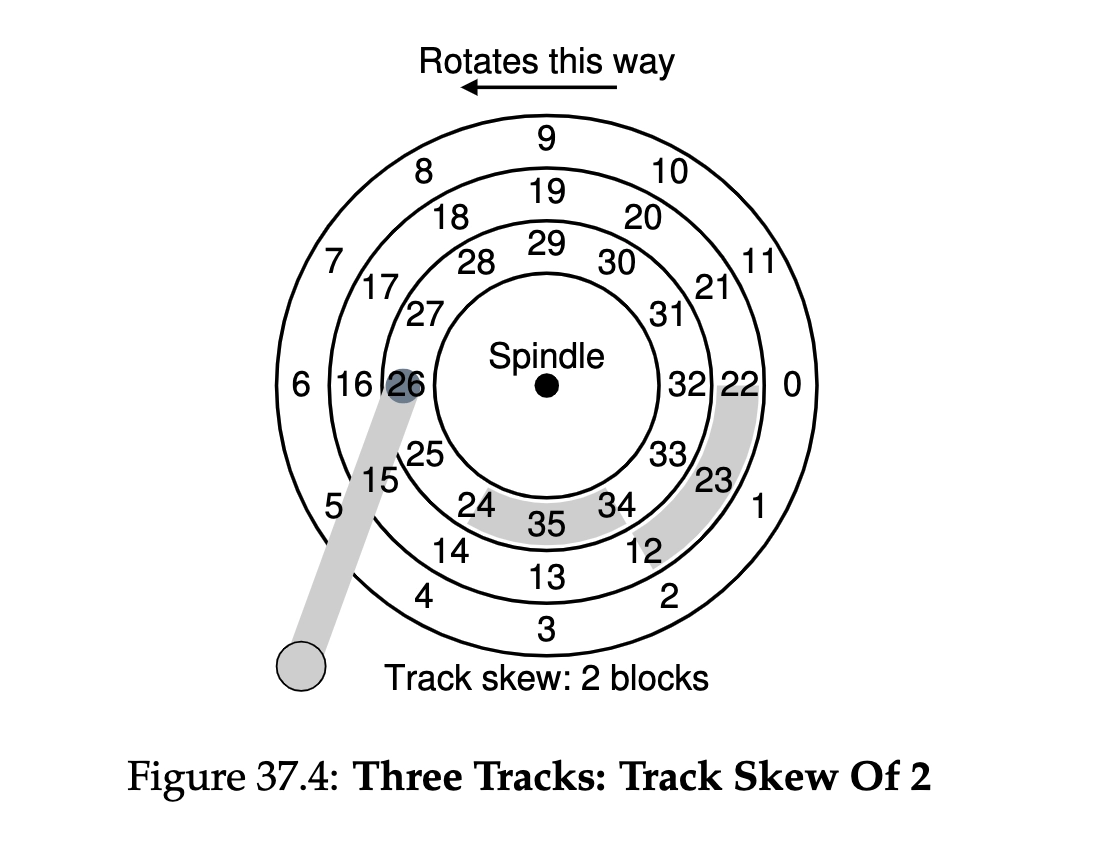
参考上图,上图表示了硬盘的一层,或者说一盘,实际硬盘是有多层堆叠起来的。我们介绍一下它
- 最上面的Rotates this way,表示了硬盘转动的方向
- 中间的点Spindle,表示了转轴,每片硬盘围绕着转轴旋转
- 图中从内到外我们可以看到分三圈,每圈上有数字,从内到外的每圈就是磁道,磁道上的数字所表示的就是磁道上的扇区
- 我们保存的数据实际上是以扇区来做划分的。例如,我们在获取数据时,只需要care数据保存在哪个扇区上
- 左下角那个圆柱体,表示了磁臂和刺头,你可以看到磁头点到了26扇区,说明目前在读写26扇区内的数据,磁头通过对应扇区中的某个点是否被磁化(表示0/1),来读取数据
结合这个构造,我们可以过一下读取数据的过程
- 用户发起读取某个文件的请求,OS获取文件系统中保存的该文件对应的磁道和扇区
- OS发送指令,告知磁盘读取指定磁道和扇区的数据
- 需要注意,整个磁头的定位过程中,磁臂和磁头是几乎不动的,它们几乎是在原地等到磁盘旋转到对应位置,然后去读取
- 为什么说几乎不动,因为磁臂会控制磁头在磁道间移动,也就是说,磁道间的移动依靠磁臂,扇区间的移动依靠磁盘转轴的旋转
IO时间的计算
在了解了磁盘的结构以及磁盘读取数据的步骤后,我们就可以计算一下磁盘IO的时间。
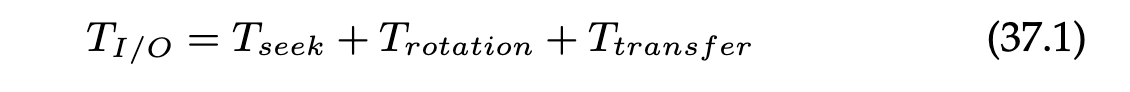
I/O的时间等于寻道时间+旋转时间(定位到扇区的时间)+数据传输时间(定位到扇区后,读写数据需要花费的时间)
很明显
- 寻道时间于磁臂移动的速度有关
- 旋转时间与磁盘转速有关
- 数据传输速度和磁盘读写速度有关
给定2个磁盘的参数,我们就可以对比2个磁盘间的IO速度差异

平均寻道时间用于计算随机读写时的情况,顺序读写时,其实寻道时间和转速基本不需要考虑,实际速度接近Max Transfer
通常上,平均寻道时间AVERAGE SEEK是最长寻道时间0-N的$\frac{1}{3}N$,这是通过对所有可能的寻道时间积分计算而来的
磁盘的调度算法
处于磁盘这种寻道和定位扇区的独特设计,磁盘对于IO请求,会有自己的调度算法,以此来提升IO效率
最短寻道时间
这个算法的思路以及实现都很简单,对于到来的IO按照磁道的远近进行排序,离当前磁道最近的IO会被优先执行,以此来减少磁道的移动时间消耗。
但是这会带来一个巨大的问题:饥饿,在这种逻辑下,位于最两侧(最内和最外)的磁道经常得不到调度,会陷入饥饿,当然,饥饿也是可以通过调度算法的设计去解决的。比如我们现在可以脑拍一个算法:对于那些太久没被调度的,会拥有一次优先调度的晋升机会,也就是再额外对每个IO请求维护一个未被调度次数,以此来降低饥饿的影响。
电梯算法
电梯算法的从命名就可以看出它的逻辑,它像电梯一般,总是从磁道最内部移动到最外部,然后再移回内部,循环往复。
电梯算法可以有效避免饥饿,但是它忽略了磁盘的旋转,大大降低了IO的效率,想象一下,当磁道由内而外移动了2圈时,你要读取的扇区都刚好错过了,或者说都刚好需要完整的等待磁盘转完一圈。
最短距离算法
因为我们可以通过当前磁头所在的磁道以及扇区位置,结合寻道时间以及转速,直接计算出从当前点(p1,s1)-(p2,s2)的cost。所以我们可以对即将进行的IO进行排序,尽可能综合寻道速度和转速,来挑选下一个执行的IO。
这种算法的缺点是需要知道磁头当前所在的位置,所以OS无法实现,这种算法现在往往由磁盘内部直接实现。
其他内容
磁盘调度由谁实现?:
现在磁盘的调度现在往往由磁盘内部直接实现,因为OS无法获取磁盘的具体详细状态(比如每个磁头位置),所以现在磁盘都自带一个芯片,以此来实现执行调度算法,并且控制磁盘的cache。
磁盘IO的合并:
磁盘往往会等待一些IO,并以一定周期来将那些可能是连续或者就近的IO合并,比如我们以s表示扇区的话,到来的IO次序分别是(s37,s1,s38)时,明显将s37与s38合并后执行,可以少等待一圈磁盘旋转的时间。
等待时间以及取舍:
不论从算法的角度,还是IO合并的角度,我们都是在做一种取舍:不马上进行到来的IO,而是在接受一定数量的IO请求以后,通过算法来调度这些IO以实现整体IO效率的提升。所以我们在发出一个IO时,往往需要等待,因为它并不是被马上执行的。所以,等待多久(多少次IO到来后进行一次决策),这是一个复杂而又困难的问题。