数据库扩容随着架构的演进
数据库扩容一般都是随着系统建设一步步演进的,所以这里随着系统的演进,一一介绍扩容的方案。
读写分离
一开始肯定是一个数据库,但是压力上来了之后,最容易做的就是读写分离,即1主多从,主机负责写,从机负责读,像mysql就提供类似功能,通过配置实现master-slaver的模式。但是读写分离的逻辑还是要在程序中写的,即配置多数据源,update与insert走主库,select走读库。耦合较高。代码侵入强。
垂直分库
读写分离也扛不住了咋办?一般这个时候随着业务的扩展,微服务即所谓的分布式服务就要开始实施了,此时可以随着系统的拆分,将数据库也拆分,如较细的拆分成:用户模块库,订单模块库,商品模块库。较粗的拆分成:核心业务库,周围业务库。这一步是通过业务进行垂直分库,非常好理解,即将不同的业务表按照属性,分配到不同的数据库中去,具体实现最简单的当然也是改动数据访问层的代码。
水平分表
垂直分库后,随着业务量上来,你会发现核心表的数据量太大,如果索引列多的话,既占空间,效率还低,按照往常流传的经验,mysql一张表500W数据就差不多了,在往上性能就会下降的厉害,所以这个时候可以进行水平分表。水平分表即将一张大表的数据,按照一定逻辑,散列到几张不同的表中,使得不会出现过大的表,提升查找效率。具体的做法一般有:
- 按照日期散列,即一个月一张表,或一周一张表,提前建立大量的表,修改程序后上线,程序自动按天写入到当天的表中去,查询时也根据数据的时间(可以根据搜索引擎等做路由),寻找到具体的那张表去查询。优点是实现简单,自带扩容(加表就行),缺点是查询略麻烦(如果是时间强相关的报表类还好,如果是普通该业务因为往往查询时不一定有数据的时间,所以可能需要路由表或搜索引擎去辅助)。
- 按照主键或业务主键哈希散列,即如用户表user,根据user_id以及哈希算法,落到具体的表中。可预先估计数据量如3年内预估10亿数据,每张表500W数据,那么共需要200张表,提前建好,命名规则为user_01到user_200。进行数据操作时先根据user_id以及哈希算法算出具体要到哪张表的表名,然后具体执行sql。优点是实现优雅,查询简单。缺点是扩容复杂(加表的话要重新计算散列哈希再次落库),不带业务主键的查询需要改造。其实和1中一样,只不过一个散列是日期一个散列是业务主键哈希,都要面对不带散列键的查询难题。
水平分库
其实水平分库我认为是和水平分表差不多级别的解决问题的方案,应该说是差不多时候考虑的,在数据库表性能先达到上限时,可以采用水平分表。当数据库性能达到上限时,可以采用水平分库。这两个水平拆分我个人认为可以在一起看,思想和达到的目的都是相同的。
水平拆分数据库最通常的思路就是做冷热库,即定时将冷数据(业务上访问量少,一般具有历史时效性,如业务只提供一年内的查询)转移到冷库中。如每年将去年的数据转移到冷库中,冷库的性能可以较低,因为历史数据的访问量低,并且历史数据查询速度慢是可以容忍的。
为什么我说和水平分表差不多呢,因为水平分库也可以做到类似分表的功能,即你之前不是路由到不同表吗,现在是每个库都建一张同名表,路由以数据库层面来做,效果其实是差不多的。
水平分库分表
最后的演进一般就是水平分库加水平分表都上,即路由结果是路由到某个分库+某个分表,比如 共200张user表,200张user表平均分布在10个数据库实例上,每个数据库实例上有20张表。
一次数据库分库分表实践
入职一段时间后,领导安排下来任务,要做数据库分库分表,确实,现在系统数据几个核心表,user,order,account这些,基本都是少则千万,多则几亿的数据,能正常面对线上需求纯靠把接口搞成纯异步加一堆MQ扔来扔去,不时还得DBA自己手动去备份一部分数据到历史库,并且程序里还没有查历史库的逻辑!
分库分表方案
最早公司是有其他系统做过分库分表的,并且方案设计文档还留存着,使用的是mycat。但是了解了一下之后,发现阿里云有类似于mycat的drds云,正好公司本来就使用的阿里云的RDS数据库实例,于是DBA推荐使用这个方式,基本后面就按照DRDS去设计了,其实也没什么差别,最后分库分表方案主要包括2方面:1. 垂直分库、2: 核心表水平分库分表。
垂直分库
首先是根据业务特性,一定要做的一个就是垂直分库,将核心业务库:订单,用户,账户等库与非核心业务库:菜单,短信,消息,推送,客诉等进行一个分库。另外就是因为历史原因,一个行程计费系统和我们App后端使用的是同一个数据库,所以借着这次也对其做一个拆分。drds是中间件性质的,所以对接入层改动没有要求,完全可以接受。
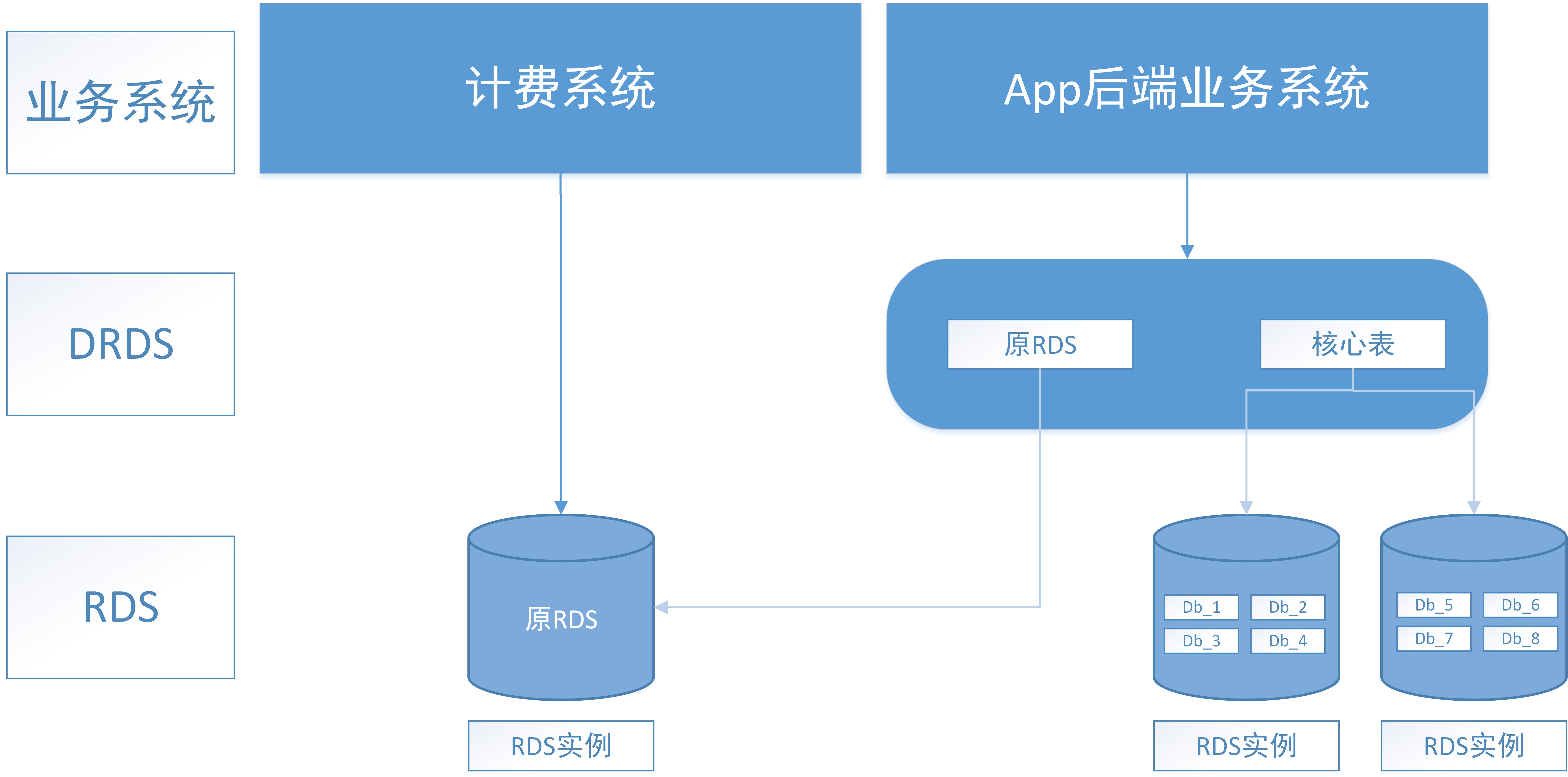
水平分库分表中遇到的难点
拆分键的选择
拆分键的选择是十分重要的一个问题,我们业务系统的拆分键理论上可以使用的有user_id,merchant_id(商户号),city_id这3个字段,在实现分库分表中,拆分键要尽量考虑以下问题:
- 拆分键哈希后的均匀程度:其中merchant_id和city_id都会导致散列的十分不均匀。
- 拆分键的改造难度:对老系统改造,当然要选取一个目前sql大多数查询都带的拆分键,其中merchant_id大多数查询都不带。
最后选择肯定还是选择了user_id作为拆分键,这样的话改动尽量小,也满足要求。
join等操作,报表系统的问题
水平分库分表后,非拆分键的查询,数据库join,范围查询等操作都会变成代价无法承受的操作。好在系统中从以前设计来看,基本通过冗余字段等手段解决了,系统中的核心表均没有join操作和复杂查询。非拆分键的查询直接使用elasticsearch来做了。但是报表系统是对数据源有大量复杂查询和范围查询的。跟报表部门沟通后,报表部门允许我们通过mq将核心数据的变更通知到报表系统,并且容忍这部分数据的一致性问题,所以这部分问题倒是顺利解决了。
索引的查询
这一定是水平分库分表都会遇到的最大的问题,即通过user_id进行拆分后,其他原表索引字段的查询该如何做?比如用户表,在查询用户是否注册时,肯定是不存在user_id,而是要通过手机号判断的,此时在原库中,手机号加了索引,但是在拆分后,不带上userid字段的查询都是噩梦。这类字段有很多,查询都是问题,当时我结合网上的资料提出了2种解决方案:
- 异构索引表。这个也是阿里的方案,阿里的用户表以及订单表等核心表,开源出叫做Canal的数据同步机制,使用mysql的binlog,来完成数据的增量同步,即同样的一张订单表,除主表是以user_id拆分外,还存在一张数据一样的,以商家id做拆分键的表,另外可能有一张数据一样的,以平台id做拆分键的表。以此类推。所以叫异构索引表。
- 通过搜索引擎,如elasticsearch等,在插入数据库后,同时将数据通过kafka等mq写到搜索引擎中,然后在后续查询时,先通过搜索引擎查询到对应索引值的拆分键,再通过拆分键去查询。
最后选择了方案1,因为方案2的不一致性问题很严重,时效性会出现问题,对于核心业务大表要做幂等的情况下,是无法容忍的。
数据迁移
上线当晚,我们对数据进行了迁移,我们首先在凌晨时把大多数流量都迁走了,只保留了几台机器提供最基本的服务,对其他应用进行升级。然后期间对数据进行迁移到DRDS,迁移成功并部署完成新的应用,,待DBA确认过数据迁移准确性,测试同学验证过应用(其中比较重要的就是预埋数据的验证)后,将流量切回升级后的程序,将剩余的部分的应用升级。后续在迁移过程中出现的数据问题,由DBA负责修复。
总结
- 在初始设计数据库以及开发时,就应该考虑后续拓展,尽量先定义好拆分键,并且使查询都带上拆分键,这样的话后面的改动就不会过于复杂。
- 进行开发高并发分布式系统时,应尽量避免join等操作。
- 他人的方案和思路值得思考和借鉴,但是还是要以实际情况为准去考虑。